
Zero trust has emerged as a cornerstone of modern enterprise security. It is mainly applied to networks, user identities, and endpoints of most organizations. However, the single layer left undersecured is the CI/CD pipeline. These systems orchestrate code validation for production deployment and do so with persistent credentials and system privileges. This contradiction is fundamentally inconsistent with the rest of the zero-trust model, in which, by default, there should be no trust in any service, identity, or connection.
But in our environment, we realized that our pipelines had been quietly left out of security scrutiny. Jobs had long-lived secrets, and build containers were reused. The amount of access reached a level beyond what should be expected for any single job. We recognized these risks, and so we deemed that our pipelines should be treated as untrusted by default. This decision radically altered how we would approach automation and access.
Acknowledging the Pipeline as an Attack Vector
The risk does not exist for pipelines. Attackers recently exploited poorly secured build systems in several high-profile incidents (Codecov, SolarWinds, TravisCI, and others). Some of these pipelines had persistent tokens, overly permissive credentials, or no artifact verification. The story is simple: if a CI or CD system is compromised, the attacker will gain a privileged foothold in the whole application’s lifecycle.
In our case, we examined the existing permissions given to build runners. The test jobs had access to IAM roles with deploy rights, secrets persisted across jobs, and a subset of containers contained caching volumes that stored the build-time credentials. None of these were isolated mistakes; they were systemic. Autonomy was supposed to conquer all, and there was a culture of assuming automation was safe.
Applying Zero Trust to CI/CD Execution
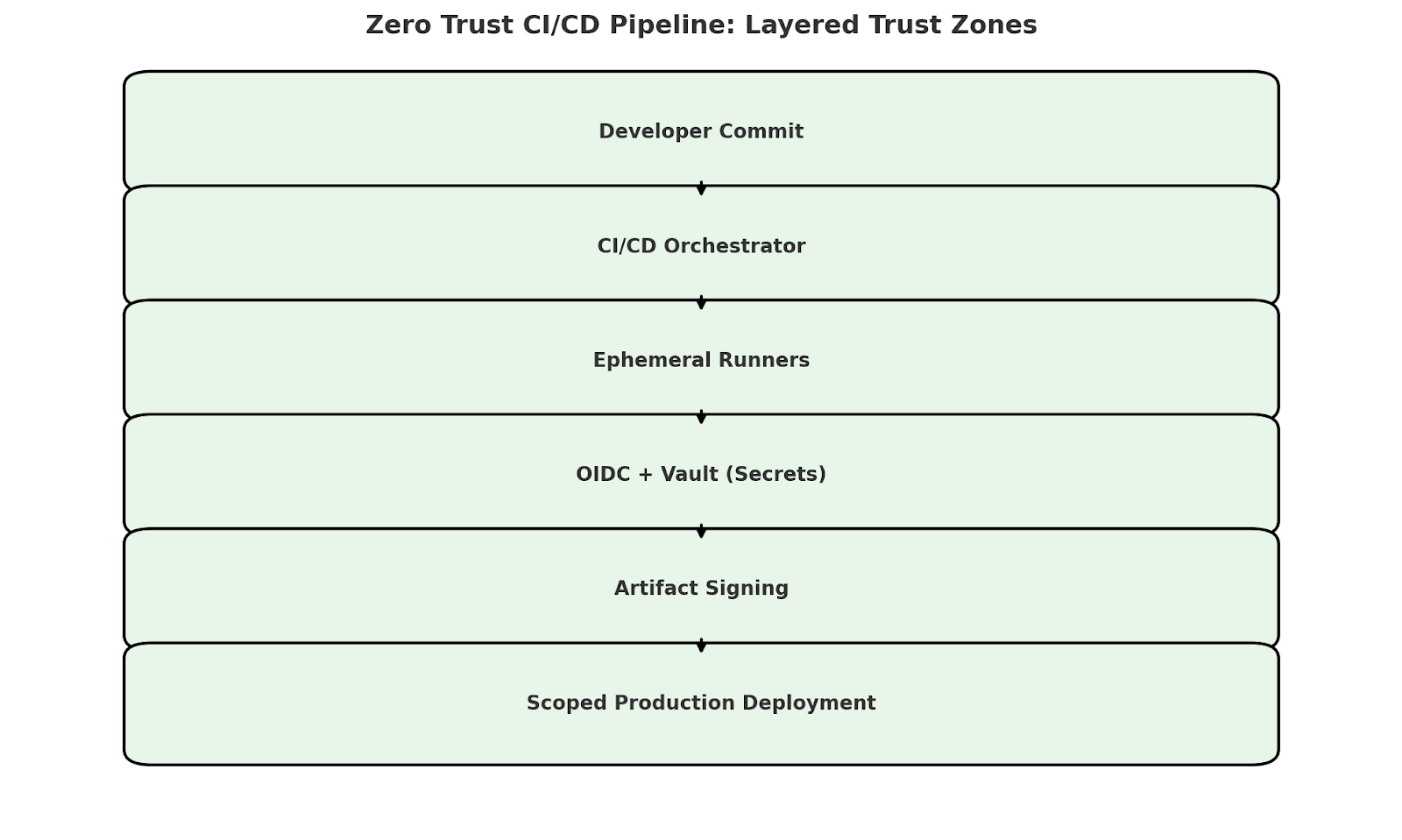
First, we approached everything CI/CD-related — runners, containers, secrets, dependencies — assuming that it could be compromised. It did not matter that the pipeline was internal; it was no longer trusted. In fully isolated containers, built jobs were executed on an on-demand basis with scoped roles and no inheritance of state. The runners were forbidden from making outbound calls unless they were authorized to do so.
We moved away from using static credentials or shared tokens and switched to short-lived identity tokens that are issued via OIDC. Because these tokens were scoped at the job level and expired immediately after execution, they were not impersonated by anyone outside of the impression code. It was logged with the options traceable to the git SHA and build ID and, thus, not reusable in any context. Once the build ended, its privileges were over. The access window available to malicious actors if they injected code into a job was reduced to minutes, and their privileges were reduced to as small as possible.
Restricting Privilege Without Compromising Deployment
Enforcing least privilege in pipelines has been one of the hardest things to do within zero-trust pipelines without breaking delivery. Most of our first jobs were given global permissions, so we had to break these down. Instead of having one runner do everything, we separated the responsibility of building, testing, and deploying into scoped individual roles. Each stage assumed only what it needed. For example, build jobs could access artifact stores, test jobs could access test environments, and deploy jobs would interact with production only with rigorous approval.
This left us with no other choice but to redesign parts of our toolchain. As such, we used signed uploads to our registry and verified those signatures downstream. For example, instead of storing artifacts in intermediate caches, we concatenated them before uploading to our registry. By doing this, the build wasn’t compromised, and its modified binaries couldn’t be spread down the pipeline. It wasn’t a tiny shift. The result was a segmented system in which every action could be traced, verified, and confined.
Verifying Identities and Artifacts at Every Step
The true meaning of zero trust extends beyond authentication and requires continuous verification. For example, we would verify the trustworthiness of the inputs and outputs in a CI/CD context. Across all of the protected branches, we enforced signed commits and tags. Every pull request had to be linked to a known, verified identity. Cosign was used to sign and build artifacts and validate against a public key infrastructure before deployment.
We recorded provenance tracking, including which jobs produced which artifacts, with which code version, and on which environment conditions. This was a total 100% traceability from commit to deployment. In case a vulnerability is reported in production, we could track the origin of the vulnerability through the signed artifacts and job logs.
Rethinking Secrets Management Under Zero Trust
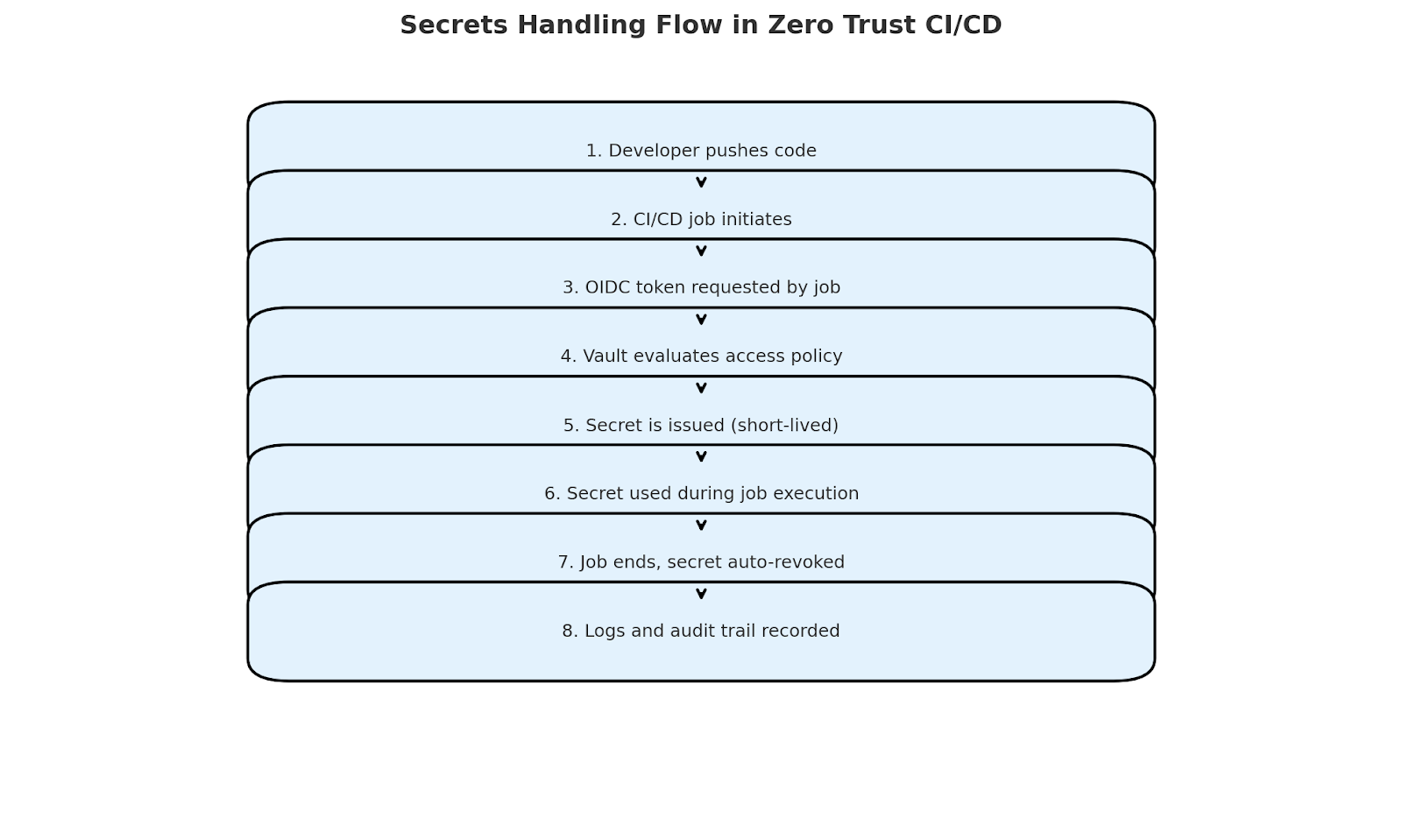
One dangerous assumption in CI/CD systems is that secrets can be safely injected into the build environment. In traditional pipelines, secrets are sent over mounted volumes or environment variables. However, if the pipeline is compromised, those secrets can be exfiltrated. To counteract this, we stopped using static secrets.
We ran secrets from Vault through a policy-gated instance with scoped secrets by identity and job context. The runner does not store any secret. Access to all secrets is time-bound, logged centrally, and IP-restricted. And if a secret is run outside of its intended job, it becomes revoked automatically. Forcing better lifecycle hygiene about credential use and, at the same time, mitigating risk was what this approach did.
Observability as a Core Zero Trust Requirement
The core of zero trust is visibility in pipelines, which includes tracking every action, credential, and job undertaken. Structured logs are emitted for each job with a job ID, repository, runner fingerprint & execution hash. These logs go into our main observability stack, which is also combined with network flow logs and cloud access logs.
For example, we deployed automated anomaly detection when a test job tried to talk to the production endpoints or when a build tried to access resources it had never seen before. This telemetry didn’t stop at response time; it actually improved. By itself, it helped us proactively tune our policies and identify patterns of risky behaviour.
Designing for Failure: Containment and Recovery
I am a big proponent of applying zero trust to CI/CD. One of the biggest benefits was improved blast radius containment. With the previous model, a compromised runner could, in principle, also pull secrets, access production, or otherwise modify artifacts downstream. Each job is now ephemeral, isolated, and cannot escalate.
This model was then validated by simulating the runner compromise. The injected payload had access only to the scoped role, no secrets, and could not transition to other jobs or services within the cluster. Logs captured every action. It caused no further harm and failed with the job. This proved that our system, though secure on paper, was also robust in the field.
Conclusion
Treating CI/CD pipelines as trusted automation poses a security risk. These systems have access to most secret resources in a software lifecycle. With the addition of zero-trust principles — isolate, least privilege, dynamic credentials, and end-to-end verification — they transition from liability to a line of defense.
To accomplish this, we had to re-engineer not just the tooling but also the assumptions behind it. We opted to move from convenience to control. The cost was a pipeline that could be hit, but the rest of our infrastructure could stand.








{kind=link}