![]()
At a large-scale model training (in huge models), anomalies are not rare events but problematic patterns that drive failure. Detecting anomalies early in the process saves days of work and training.
![]()
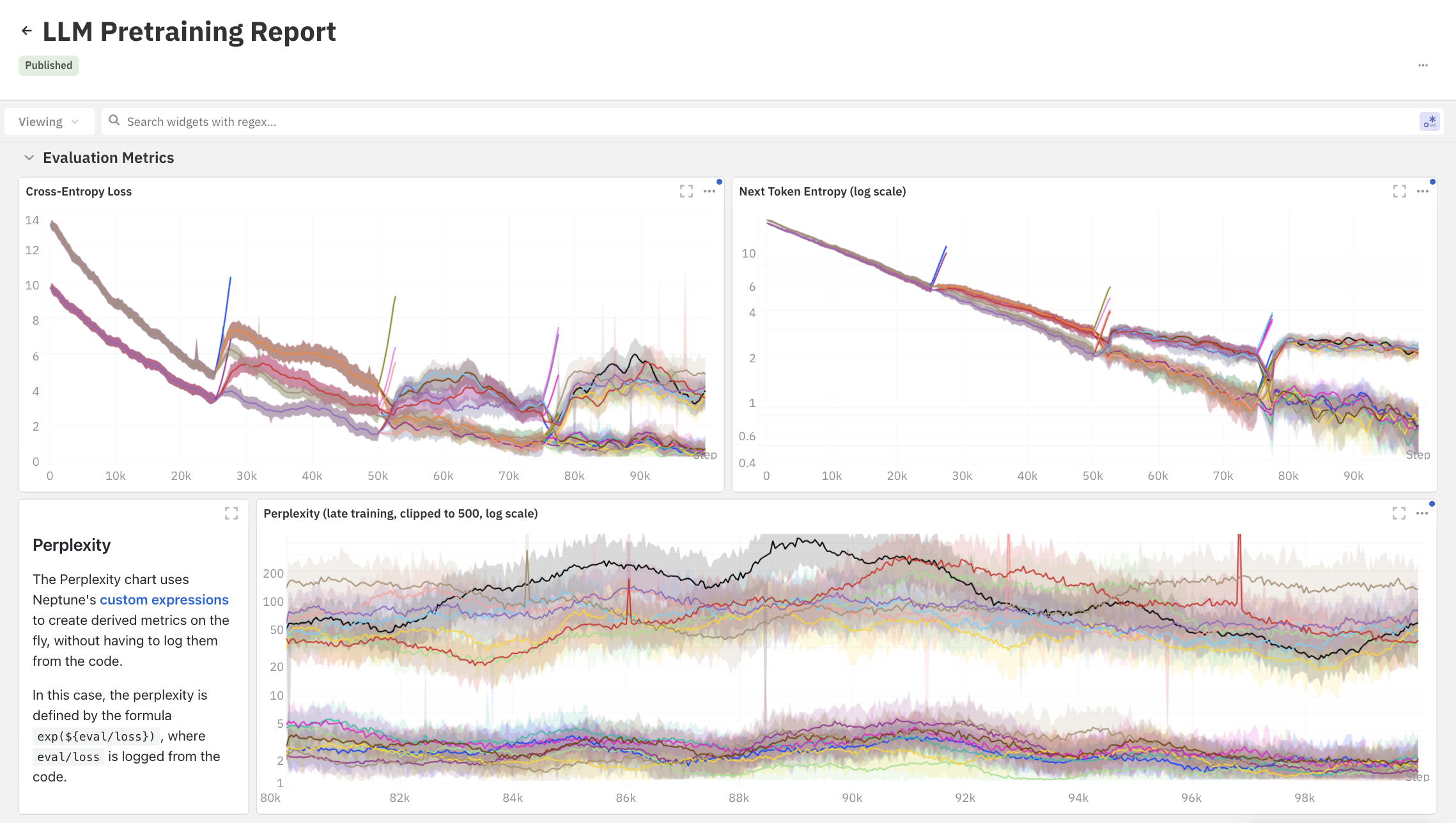
ML model training observability is not just about tracking metrics. It requires proactive monitoring to catch issues early and ensure model success, given the high cost of training on large GPU clusters.
![]()
If you are an enterprise or a team operating a model, focus on three key areas: fine-tune your prompts to get the most effective outputs (prompt engineering), ensure that your model behaves safely and predictably, and implement robust monitoring and logging to track performance, detecting issues early.
![]()
neptune.ai experiment tracker supports fault tolerance and is designed to maintain progress despite hardware failures, making it adaptable for enterprise teams tackling LLM fine-tuning, compliance, and building domain-specific models.
Scaling large language model (LLM) operations is a challenge that many of us are facing right now. For those navigating similar waters, I recently shared some thoughts about it on the Data Exchange Podcast based on our journey at neptune.ai over the last few years.
Six years ago, we were mainly focused on MLOps when machine learning in production was still evolving. Experiment tracking back then was straightforward—dealing mostly with single models or small-scale distributed systems. Reinforcement learning was one of the few areas pushing the boundaries of scale. In that reinforcement learning, we wanted to run multiple agents and send data from multiple distributed machines to our experiment tracker. This was a huge challenge.
Scaling LLMs: from ML to LLMOps
The landscape changed two years ago when people started training LLMs at scale. LLMOps has taken center stage, and the importance of scaling large language models has grown with research becoming more industrialized. While researchers continue to lead the training process, they are also adjusting to the transition toward commercial applications.
LLMOps isn’t just MLOps with bigger servers, it is a paradigm shift for tracking experiments. We’re not tracking a few hundred metrics for a couple of hours anymore; we’re tracking thousands, even tens of thousands, over several months. These models are trained on GPU clusters spanning multiple data centers, with training jobs that can take months to complete.
Due to time constraints, training frontier models has become a production workflow rather than experimentation. When a training from scratch run takes 50,000 GPUs over several months in different data centers, you don’t get a second chance if something goes wrong—you need to get it right the first time.
Another interesting aspect of LLM training that only a few companies have truly nailed is the branch-and-fork style of training—something that Google has implemented effectively. This method involves branching off multiple experiments from a continuously running model, requiring a significant amount of data from previous runs. It’s a powerful approach, but it demands infrastructure capable of handling large data inheritance, which makes it feasible only for a handful of companies.
From experiment tracking to experiment monitoring
Now we want to track everything—every layer, every detail—because even a small anomaly can mean the difference between success and failure and many hours of work wasted. During this time, we should not only consider pre-training and training time; post-training takes a huge amount of time and collaborative human work. Grasping this issue, we have re-engineered Neptune’s platform to efficiently ingest and visualize massive volumes of data, enabling fast monitoring and analysis at a larger scale.


One of the biggest lessons we’ve learned is that experiment tracking has evolved into experiment monitoring. Unlike MLOps, tracking is no longer just about logging metrics and reviewing them later or restarting your training from a checkpoint a few steps back. It’s about having real-time insights to keep everything on track. With such long training times, a single overlooked metric can lead to significant setbacks. That’s why we’re focusing on building intelligent alerts and anomaly detection right into our experiment tracking system.
Think of it like this—we’re moving from being reactive trackers to proactive observers. Our goal is for our platform to recognize when something is off before the researcher even knows to look for it.
Fault tolerance in LLMs
When you’re dealing with LLM training at this scale, fault tolerance becomes a critical component. With thousands of GPUs running for months, hardware failures are almost inevitable. It’s crucial to have mechanisms in place to handle these faults gracefully.
At Neptune, our system is designed to ensure that the training can resume from checkpoints without losing any data. Fault tolerance does not only mean preventing failures; it also includes minimizing the impact when they occur, so that time and resources are not wasted.
What does this mean for enterprise teams?
If you’re creating your own LLMs from scratch, or even if you’re an enterprise fine-tuning a model, you might wonder how all this is relevant to you. Here’s the deal: strategies originally designed for handling the massive scale of training LLMs are now being adopted in other areas or by smaller-scale projects.
Today, cutting-edge models are pushing the boundaries of scale, complexity, and performance, but these same lessons are starting to matter in fine-tuning tasks, especially when dealing with compliance, reproducibility, or complex domain-specific models.
For enterprise teams, there are three key focuses to consider:
- Prompt Engineering: Fine-tune your prompts to get the most effective outputs. This is crucial for adapting large models to your specific needs without having to train from scratch.
- Implement guardrails in your application: Ensuring your models behave safely and predictably is key. Guardrails help manage the risks associated with deploying AI in production environments, especially when dealing with sensitive data or critical tasks.
- Observability in your system: Observability is vital to understanding what’s happening inside your models. Implementing robust monitoring and logging allows you to track performance, detect issues early, and ensure your models are working as expected. Neptune’s experiment tracker provides the observability you need to stay on top of your model’s behavior.
The future: what we’re building next
At Neptune, we’ve nailed the data ingestion part—it’s fast, reliable, and efficient. The challenge for the next year is making this data useful at scale. We need more than just filtering; we need smart tools that can surface the most critical insights and the most granular information automatically. The goal is to build an experiment tracker that helps researchers discover insights, not just record data.
We’re also working on developing a platform that combines monitoring and anomaly detection with the deep expertise researchers acquire over years of experience. By embedding that expertise directly into the tool (either automatically or by defining rules manually), less experienced researchers can benefit from the patterns and signals that would otherwise take years to learn.








{kind=link}