
Kubernetes has become the de facto solution for container orchestration when deploying applications in the cloud. It enables developers to scale applications easily and provides reliable management.
However, cluster sizing is one crucial factor in determining the performance and cost efficiency of your Kubernetes deployment. In this article, we will examine how Kubernetes cluster sizing affects these two crucial factors and give actionable insights on how to improve your cloud environment.
Understanding Kubernetes Cluster Sizing
Kubernetes cluster sizing is the process of defining how many computational resources (CPU, RAM, and storage) need to be assigned to the nodes of your Kubernetes cluster. Getting the sizing right is essential to ensure your system will run without spending more than necessary on unnecessary resources and sacrificing application performance.
For a deeper dive into Kubernetes architecture and how it handles resource management, check out the Kubernetes Official Docs.
The Performance Implications of Cluster Sizing
Under-Provisioning: When Your Cluster Is Overloaded
Under-provisioning cluster sizing is one of the primary concerns, namely because you are not allocating enough resources. As a result, the Kubernetes cluster is forced to share resources with multiple workloads, meaning that unless your Kubernetes cluster is planned and deployed correctly, your workloads may be impacted negatively.
In the case of CPU starvation or memory reasons, pods may fail or get evicted from the nodes. Pods being evicted out of memory results in a downtime for an application, which impacts the user experience. Furthermore, under provisioning can increase the latency due to Kubernetes struggling to balance the allocation of resources between competing workloads.
Therefore, as tempting as it is to under-provision at first to save costs, it ultimately results in poor performance, which could cost your company more in lost users or degraded service quality.
Over-Provisioning: The Hidden Cost of Idle Resources
Over-provisioning on the other hand entails allocating more capacity than is required, resulting in an excess of unused capacity. This guarantees you won’t have any performance issues with your cluster, but comes with a different problem: extra costs.
Cloud providers typically charge for the resources used, which means that if you allocate more CPUs or memory than you need, you are paying for resources that are going unused. It can quickly turn into a drain on your business’s budget. Autoscaling nodes and pods in Kubernetes can match load, but constant over-provisioning negates this benefit and leads to significant cost inefficiencies.
Striking the Right Balance: Optimizing Kubernetes Cluster Sizing
The key to maximizing both performance and cost efficiency lies in achieving the balance between the under-provisioning and over-provisioning. Horizontal Pod Autoscaling (HPA) and Cluster Autoscaler are some of the important Kubernetes autoscaling features in this situation.
- Horizontal Pod Autoscaler (HPA) provides auto-scale of the number of pod replicas in real-time. Increasing workload will trigger HPA to add more replicas to manage the load and prevent your services from going down.
- Cluster Autoscaler scales the number of nodes automatically based on the amount of pods and the resources they need, avoiding dealing with having to manually adjust the cluster size.
Together, these tools dynamically optimize resource usage with little impact on performance and avoid paying unnecessary costs. To understand how Kubernetes automates scaling to meet demand, refer to the detailed guide on autoscaling in Kubernetes.
The Cost Efficiency Factor: Why Sizing Matters
The Cloud Cost Model and Its Impact on Sizing
When it comes to a pay-as-you-go cloud model, every allocated resource will incur a cost. Your Kubernetes cluster sizing, more or less, directly affects what you have to pay for your infrastructure. If service disruptions happen due to under-provisioning, it may necessitate more resources and end up being costly in the long run. The above-mentioned issue results in wasted capacity that inevitably makes its mark on your bottom line.
You would want to right-size your Kubernetes cluster to minimize costs. With both node types and resource allocation adjusted accordingly to help cater to workload needs, you are not overcompensating and are only paying what you need.
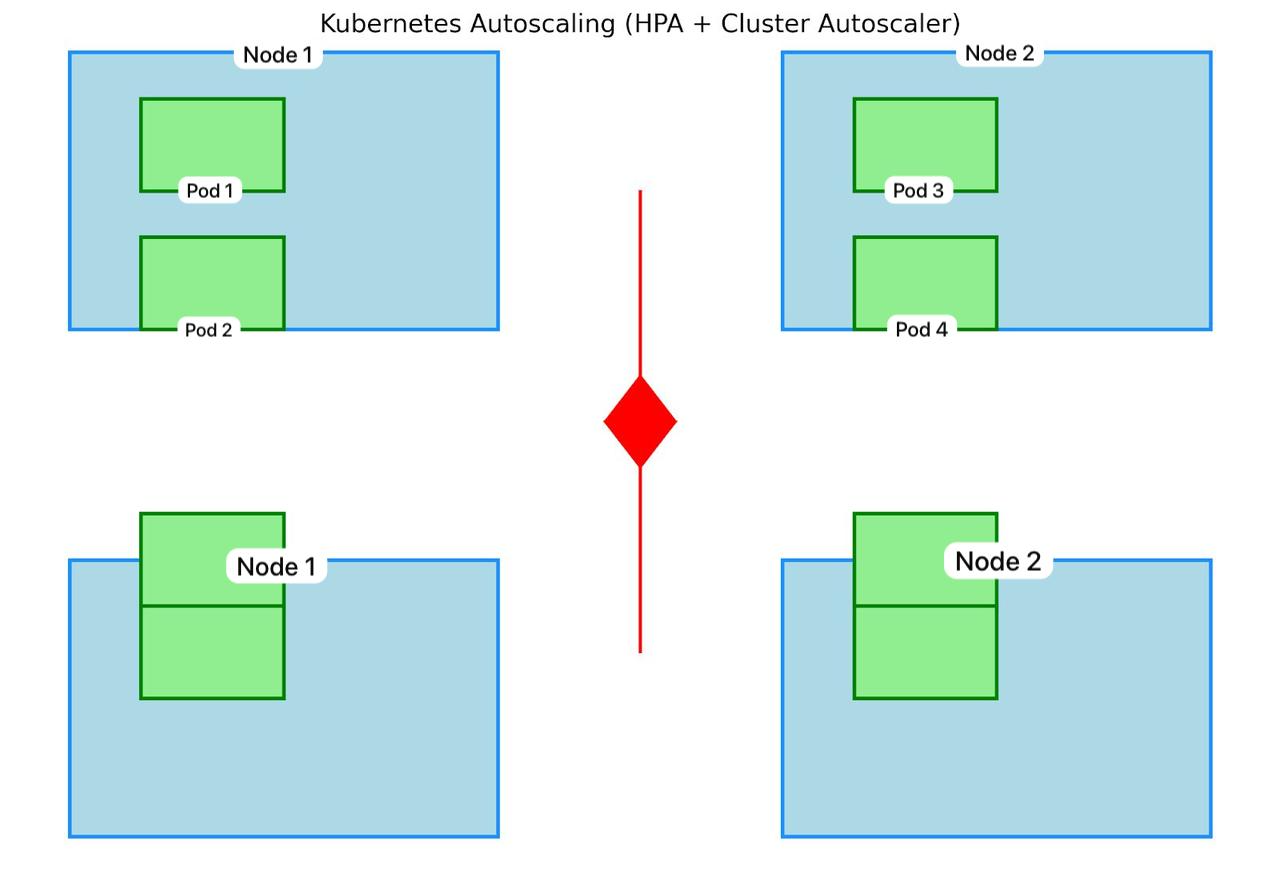
Best Practices for Sizing Your Kubernetes Cluster
To keep your Kubernetes cluster running optimally both in terms of performance and cost, it is encouraged to follow these best practices.
- Regularly monitor: CPU, memory, and network usage of your cluster. Prometheus and Grafana are tools that can aid you in visualizing resource consumption and taking data-driven decisions on how big your cluster should be.
- Enable auto-scaling features: Set up HPA, VPA, and Cluster Autoscaler that will automatically manage resources depending on the actual demand. In addition, this prevents two other scenarios we covered earlier: under provisioning and over provisioning your cluster.
- Use multiple node pools: Depending upon what kinds of workloads your cluster will be running, you may want to use multiple node pools. This lets you assign particular resource types to applications based on what type of workloads should be used in that same application, like big computing-intensive workloads, utilizing huge, powerful nodes, and smaller nodes for lighter services, which are going to improve the performance as well as the cost.
Kubernetes environments are dynamic, and your application will require different resource allocation as your application evolves. Constantly check and modify your cluster configurations so your cluster is tuned following the latest usage profiles.
Conclusion
Kubernetes cluster sizing is a fine balance that directly impacts the performance and value of the cloud application. With both under- and over-provisioning avoided and automation with Kubernetes auto scaling on board, you can be confident that your infrastructure is well tuned and operating at its maximum capacity.
Autoscaling, monitoring, and node pooling are all very important practices that will help you optimize your cluster and also save costs during the process. Sizing your infrastructure properly not only translates into maximum performance but also means it is within your budget and easily scalable.







{kind=link}