Imagine asking an AI not only to describe an image, but to understand it, respond to a question about it, or even take action based on what it sees and hears. This isn’t science fiction anymore. It’s the promise of a new wave in AI called Perception Language Models (PLMs).
In a world where artificial intelligence is learning to reason across vision, text, and even sound, PLMs are reshaping how machines perceive and respond to the world. So what exactly are they? Why do they matter? And where are they taking us?
Let’s unpack it.
What Are Perception Language Models?
Traditional language models like ChatGPT or BERT operate within the realm of pure text. They read, generate, summarize, and translate, but they don’t understand the world visually or auditorily.
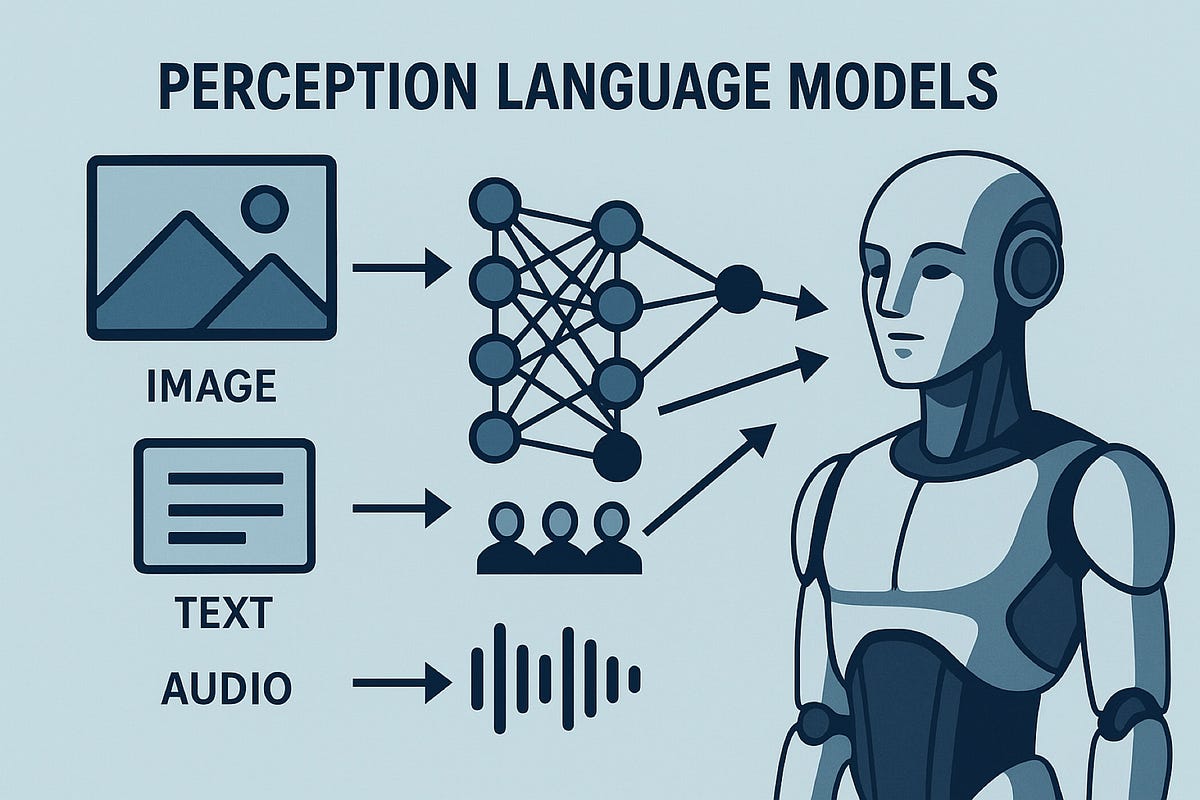
Perception Language Models go a step further. These models are trained to process multiple forms of input auch as text, images, audio, even video and connect them meaningfully. They’re not just reading or watching, they’re interpreting, fusing, and reasoning across modalities.
Think of a PLM as an AI that doesn’t just understand words but also understands what it’s looking at or listening to.

Why Are PLMs a Big Deal?
Because the real world isn’t made of just words.
When a human sees a dog chasing a ball, hears a bark, and reads a warning sign, they instinctively connect all of that information. But for AI, these are traditionally separate tasks: a vision model sees the dog, an NLP model reads the sign, and an audio model hears the bark. PLMs unify that process.
This unlocks:
• Smarter AI assistants that understand both what you’re saying and what you’re showing them.
• Interactive robots that can take voice commands and act based on their environment.
• AI tutors that can explain graphs, solve handwritten equations, and respond to spoken queries, all in one interface.
How Do PLMs Actually Work?
At the core of PLMs is the idea of shared understanding, also called a joint embedding space. It’s a space where the meaning of a sentence, an image, and even a sound clip can live together.
Most PLMs use:
• Encoders to convert different types of input (e.g., an image or sentence) into a vector, a numerical representation of meaning.
• Attention mechanisms to find connections across modalities. For example, linking the phrase “red car” to the actual red object in an image.
• Fusion layers to integrate these diverse signals into a coherent response.
If that sounds complex and it is. But you can imagine it like this:
“The model learns to look, listen, and read, and then respond as if it truly understood.”
Examples of PLMs in Action
Let’s explore some real-world examples where PLMs are already making waves:
GPT-4o (OpenAI)
• Combines text , vision and audio
• Can take screenshots or images and answer questions about them
• Can hold conversations with tone recognition
Kosmos-2 (Microsoft)
• Understands images and language jointly
• Powers vision-language tasks like captioning and grounding
Gato (DeepMind)
• A generalist agent that can play Atari games, chat, and control robots, all using a shared model
MiniGPT-4 / LLaVA / OpenFlamingo
• Open-source PLMs used for visual question answering, captioning, and image-grounded conversations
Real-World Applications
Education
AI tutors that can explain charts, diagrams, and handwritten equations with spoken explanations.
Healthcare
Medical PLMs that interpret X-rays or MRIs alongside a doctor’s notes and generate diagnoses or summaries.
Robotics
Robots that understand commands like “Pick up the blue mug on the left of the sink”, requiring vision and language comprehension.
Accessibility
Assisting visually impaired users by interpreting surroundings through speech and images.
Challenges on the Road
Despite their potential, PLMs aren’t perfect.
• Hallucinations: They can make false claims, especially when fusing modalities.
• Biases: Multimodal data can carry harmful stereotypes.
• Compute-intensive: Training PLMs requires massive datasets and GPU power.
• Generalization: Many models still struggle outside of narrow benchmarks.
But the pace of progress is astonishing. As foundation models continue to evolve, PLMs are becoming more grounded, more accurate, and more useful by the day.
What’s Next?
PLMs could be the foundation for true general AI systems, ones that understand the world as we do: with all our senses working together. As these models learn to perceive the world, they will likely transform how we interact with machines forever.
So next time you upload a picture to your AI assistant, or ask a question using a diagram, know that you’re tapping into one of the most powerful frontiers of artificial intelligence: perception.
Conclusion
Perception Language Models are more than just an upgrade to language models, they’re a step toward truly intelligent systems that can see, hear, and understand the world in a way that’s closer to how we do. As AI becomes more multimodal, we’re moving closer to assistants, agents, and tools that can meaningfully engage with reality, not just text.
The future of AI isn’t just about better words. It’s about better understanding, and PLMs are leading that charge.








{kind=link}