
As diffusion models dominating visual content generation, efforts have been made to adapt these models for multi-view image generation to create 3D content. Traditionally, these methods implicitly learn 3D consistency by generating only RGB frames, which can lead to artifacts and inefficiencies in training. In contrast, we propose generating Normalized Coordinate Space (NCS) frames alongside RGB frames. NCS frames capture each pixel’s global coordinate, providing strong pixel correspondence and explicit supervision for 3D consistency. Additionally, by jointly estimating RGB and NCS frames during training, our approach enables us to infer their conditional distributions during inference through an inpainting strategy applied during denoising. For example, given ground truth RGB frames, we can inpaint the NCS frames and estimate camera poses, facilitating camera estimation from unposed images. We train our model over a diverse set of datasets. Through extensive experiments, we demonstrate its capacity to integrate multiple 3D-related tasks into a unified framework, setting a new benchmark for foundational 3D model.
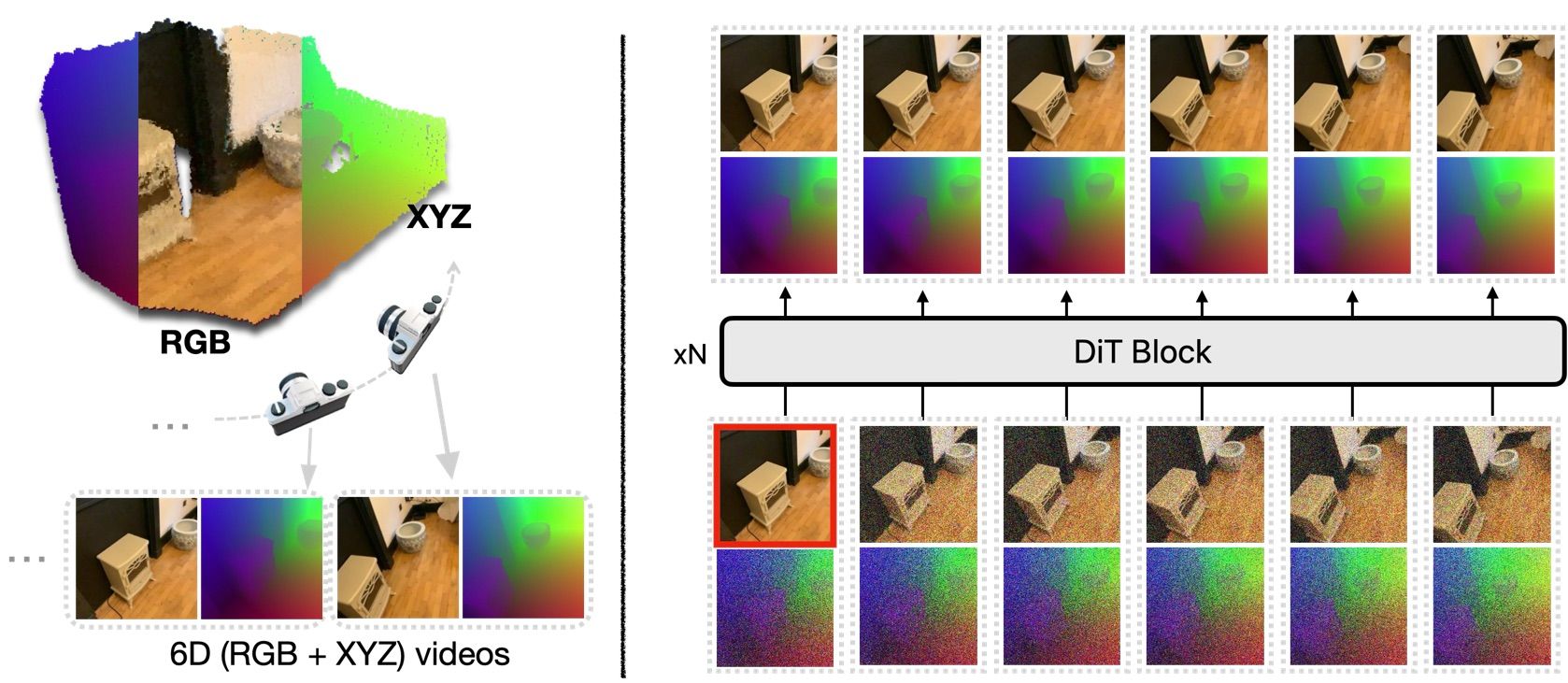
Figure 1: Pipeline of the proposed World-consistent Video Diffusion Model.
- † The Chinese University of Hong Kong
- ‡ Work done while at Apple









{kind=link}